AudioMark™
Introduction
The EEMBC AudioMark™ Benchmark is the first-of-its-kind audio benchmark that incorporates advanced signal processing, multiple data types, and a convolutional neural net in a single benchmark with a realistic code footprint. The result of over a year collaboration between top industry experts, AudioMark represents a modern workload to address the growing compute needs of low-power wireless devices that rely on speech processing.
In one way, AudioMark represents a departure from our benchmarks of recent years, which have focused primarily on measuring performance and power on specific tasks like Wi-Fi or BLE. These task-specific benchmarks are still crucial, but as a benchmark organization, our job is to make sure our benchmarks are relevant to the latest trends, and today that is AI-assisted audio at the edge. A compute-heavy benchmark like AudioMark brings us back to our MCU roots.
Audio processing is an extremely variable computing task, with performance dependent on far more than just the speed and power consumption of individual steps in the pipeline. Listening for a single word or phrase (“lights on!”) is a vastly different task from understanding a vocabulary of 20 words, for example. Whether that language is processed locally or sent to the cloud adds another set of variables. So does the decision to use floating- or fixed-point, and how big of a cache to use, if one is employed. And if you’re working with multiple audio streams, for example when identifying speakers, performance can vary even further. More broadly, the right balance of accuracy and speed against hardware investment is unique to every device and application. The result is a ubiquitous processing task whose overall performance is nearly impossible to predict from its component processes.
Fortunately, the structure of the audio processing pipeline is fairly consistent, with a few key variations. Nearly all of these pipelines start with a microphone with 16-bit output at 44.1 kHz, which then undergoes spectral analysis via Fourier transform. If the direction of the signal is important (to identify who’s speaking, for example), then a beam-forming process comes next. Echo and noise cancellation is nearly requisite. Beyond that, there’s a clear split between language analysis tasks (smart speakers and other voice controlled devices) and hearing assistance, but within these two broad groups, a lot of the processing is predictable.
Taking these consistencies and variables into account, what’s clearly needed is a customizable end-to-end benchmark with a few specific options. Providing the right amount of flexibility—without creating a benchmark so variable that it becomes meaningless—means working with experts, and we’ve recruited some good ones. Intel, Arm, onsemi, Renesas, Infineon, STMicroelectronics, Synopsys, and Texas Instruments were instrumental in making this happen.
AudioMark Overview
The typical audio pipeline of today combines technologies that date back to radar and RF broadcasting of the early 20th century--such as beamforming and direction of arrival--as well as more modern filters like acoustic echo cancellation and noise suppression. Keeping in line with recent tech trends, we've added a neural net to perform keyword-spotting or wake-word classification. AudioMark will exercise different data formats, increase the instruction cache demand, and even allow integration of acceleration such as DSPs or other dedicated audio hardware. However, it will be sufficiently balanced to not allow any one technology to dominate.
The diagram below illustrates a rough outline of the benchmark's pipeline (excluding physical transducers):
The key components consist of:
- Spectrum decomposition analysis
- Direction of arrival
- Beamforming
- Acoustic echo cancellation
- Single-channel noise-suppression
- Feature extraction
- Neural net classification
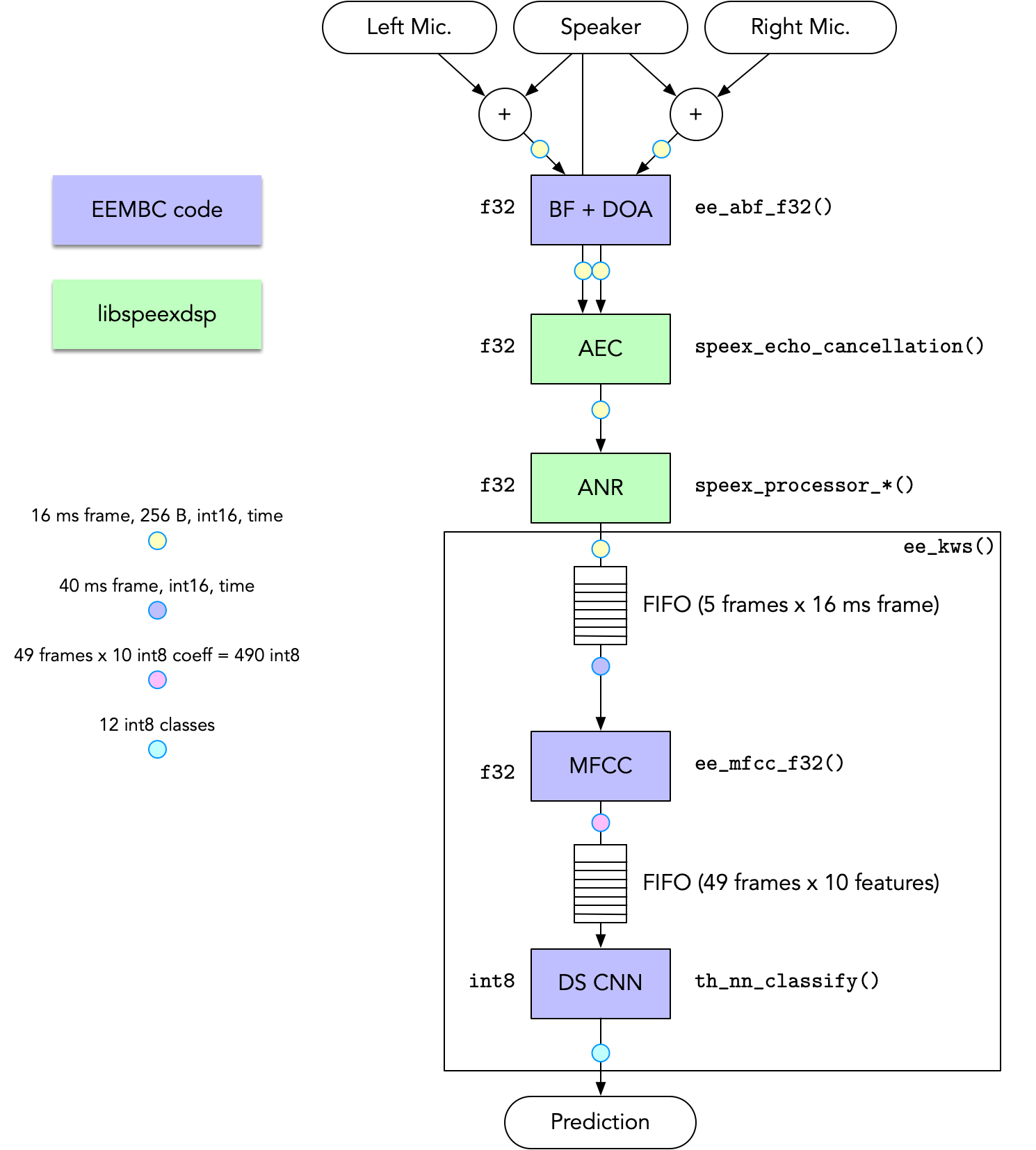
The benchmark is provided in C code with multiple porting layers. This enables adaptation to a wide variety of DSP and neural-net hardware. Please refer to the GitHub documentation for more information. Reference code is provided based on the Arm CMSIS C-library and the SpeeX open-source project, however this code can be modified at many different levels. In order to ensure that the benchmark is run properly, there are multiple unit tests that must pass with a reasonable signal-to-noise ratio when compared to reference data. This prevents over-optimization, which would impair the ability to compare scores across different platforms.
Download and get testing!
Download the benchmark source code from our GitHub repository.