About the EEMBC FPMark™ Floating-Point Benchmark Suite
FPMark is the embedded industry's first floating-point benchmark software suite. Floating point arithmetic is crucial for embedded applications such as audio, video, DSP, graphics, automotive, and motor control. In the same way that CoreMark® was intended to be a “better Dhrystone”, FPMark provides something better than the “somewhat quirky” Whetstone and Linpack.
While several FP benchmarks already exist in general use (i.e. Linpack, Nbench, Livermore loops), there hasn't been an effort to standardize the version, or the method by which the tests are run. FPMark solves both of these problems.
FPMark consists of a number of kernels which are configured into workloads. The workloads differ by the floating-point precision: single-precision (SP) and double-precision (DP); and by dataset size (small, medium, large). These permutations reflect a broad range of microcontrollers and platforms.
FPMark is multicore-ready. It is built on the EEMBC Multi-instance Test Harness (MITH) which allows runtime configuration of the number of contexts or workers to examine the parallel performance of a platform. The kernels are grouped into different marks which help summarize performance. The MITH framework requires very little FP library support, and is POSIX-thread compatible (there is also a single-thread version if no threading library is supported). RToS, baremetal, and Linux are supported.
All workloads are self-verifying, meaning the expected results are compared against a "gold standard" generated by IEEE 64-bit precision.
To help answer some basic questions, we've writen an introduction to FPMark.
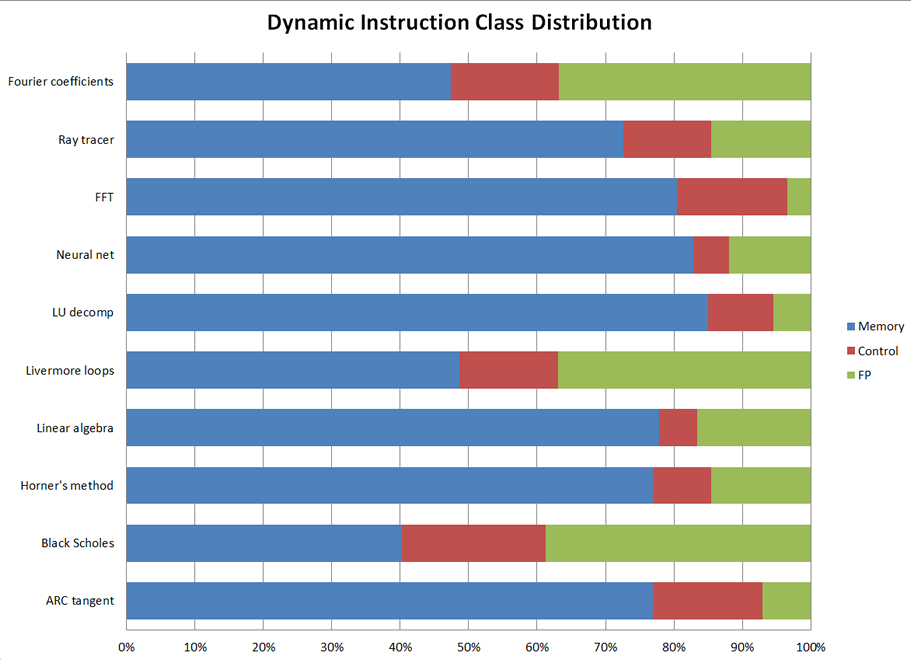
Algorithms
Here is a list of the algorithms used in FPMark (and the kernel name used in the source code). Each algorithm is run with three different dataset sizes and both single- and double-precision.
- ArcTan (
atan): Calculates angles of right triangle by using the ratio of two sides of the triangle to calculate the angle between them. - Black-Scholes (
blacks): A mathematical model for the dynamics of a financial market containing derivative investment instruments. - Horner's Method (
horner): A method to approximate the roots of a polynomial; more information at Wikipedia. - Fast Fourier Transform (
radix2): Takes any function and converts it to an equivalent set of sine waves; applications such as audio, spectral analysis, and image compression (computed at radix 2). - Linear Algebra (
linear_alg): Derived from Linpack; useful for understanding balancing forces in structural engineering, converting between reference frames in relativity, solving differential equations, and understanding rotation and fluid flow, for example. - Enhanced Livermore Loops (
loops,inner-product): This one kernel contains two dozen real-world functions extracted from programs used at Lawrence Livermore Labs. They are used to test the computational capabilities of parallel hardware and cover areas such as 2D Particle-in-Cell, Tri-diagonal Elimnation and Planckian Distribution. - LU Decomposition (
lu): Performs lower-upper matrix decomposition. - Neural Net (
nnet): A small neural-net inference engine. - Ray-Tracer (
ray): A technique for image generation by tracing light path through pixels in an image plane and simulating the effects of its encounters with virtual objects. - Fourier Coefficients (
xp1px): Numerical analysis routine for calculating series or representing a periodic function by a discrete sum of complex exponentials, also known as (x+1)^x, defined on the interval [0+epsilon,2-epsilon].
Example Output
Out of the box, FPMark can be compiled using the GNU make utility, and for convenience, a PERL script computes all of the summary marks from the dozens of component runs. Here is example output running all of the kernels and computing all of the marks. In the example below, each of the kernels is run with three different dataset sizes (small, medium, large) and both single-precision (SP) and double-precision (DP). The final marks reflect different groupings of these kernel results' geometric means. The benchmark was run with XCMD='-c4' which runs the benchmark with four contexts. When compared to a single core run, the last column indicates the scaling factor between four contexts and one.
% make TARGET=macos certify-all XCMD='-c4'
WORKLOAD RESULTS TABLE
MultiCore SingleCore
Workload Name (iter/s) (iter/s) Scaling
------------------------------------------------ ----------- ------------ ------------
atan-1M 144.93 47.8469 3.0290
atan-1M-sp 172.41 59.8802 2.8793
atan-1k 188679.25 53475.9358 3.5283
atan-1k-sp 217391.30 60975.6098 3.5652
atan-64k 3246.75 888.0995 3.6558
atan-64k-sp 3759.40 983.2842 3.8233
blacks-big-n5000v200 16.34 4.9652 3.2909
blacks-big-n5000v200-sp 21.55 6.5703 3.2802
blacks-mid-n1000v40 400.00 123.4568 3.2400
blacks-mid-n1000v40-sp 526.32 161.2903 3.2632
blacks-sml-n500v20 1666.67 500.0000 3.3333
blacks-sml-n500v20-sp 2000.00 625.0000 3.2000
horner-big-100k 598.80 169.2047 3.5389
horner-big-100k-sp 606.06 169.2047 3.5818
horner-mid-10k 6097.56 1686.3406 3.6159
horner-mid-10k-sp 6097.56 1686.3406 3.6159
horner-sml-1k 58139.53 16129.0323 3.6047
horner-sml-1k-sp 58139.53 16181.2298 3.5930
inner-product-big-100k 79.68 42.3729 1.8805
inner-product-big-100k-sp 138.89 58.9971 2.3542
inner-product-mid-10k 1606.43 571.4286 2.8112
inner-product-mid-10k-sp 2259.89 720.7207 3.1356
inner-product-sml-1k 23255.81 7407.4074 3.1395
inner-product-sml-1k-sp 31250.00 8333.3333 3.7500
linear_alg-big-1000x1000 1.90 1.2509 1.5198
linear_alg-big-1000x1000-sp 4.90 2.5694 1.9060
linear_alg-mid-100x100 980.39 292.3977 3.3529
linear_alg-mid-100x100-sp 1515.15 420.1681 3.6061
linear_alg-sml-50x50 6410.26 1811.5942 3.5385
linear_alg-sml-50x50-sp 7812.50 2222.2222 3.5156
loops-all-big-100k 0.93 0.4135 2.2547
loops-all-big-100k-sp 1.12 0.4770 2.3535
loops-all-mid-10k 19.67 5.4951 3.5795
loops-all-mid-10k-sp 22.48 6.3540 3.5382
loops-all-tiny 9803.92 2793.2961 3.5098
loops-all-tiny-sp 10638.30 3048.7805 3.4894
lu-big-2000x2_50 20.16 6.4433 3.1290
lu-big-2000x2_50-sp 20.24 6.4893 3.1194
lu-mid-200x2_50 1760.56 476.8717 3.6919
lu-mid-200x2_50-sp 1754.39 479.6163 3.6579
lu-sml-20x2_50 20242.92 5488.4742 3.6883
lu-sml-20x2_50-sp 20366.60 5515.7198 3.6925
nnet-data1-sp 24390.24 6802.7211 3.5854
nnet_data1 18867.92 5347.5936 3.5283
nnet_test 33.22 10.6270 3.1262
nnet_test-sp 33.90 10.8696 3.1186
radix2-big-64k 1669.45 450.8566 3.7028
radix2-mid-8k 25773.20 6988.1202 3.6881
radix2-sml-2k 187969.92 51867.2199 3.6241
ray-1024x768at24s 0.11 0.0283 3.7279
ray-320x240at8s 2.71 0.8635 3.1384
ray-64x48at4s 150.60 41.9111 3.5934
xp1px-big-c10000n2000 2.01 0.6384 3.1537
xp1px-mid-c1000n200 188.68 62.5000 3.0189
xp1px-sml-c100n20 24390.24 6666.6667 3.6585
MARK RESULTS TABLE
Mark Name MultiCore SingleCore Scaling
----------------------------------------------- ---------- ---------- ----------
FPMark 66007.92 20419.76 3.23
FPv1.0. DP Small Dataset 14723.08 4183.84 3.52
FPv1.1. DP Medium Dataset 458.69 137.21 3.34
FPv1.2. DP Big Dataset 16.43 5.84 2.81
FPv1.3. SP Small Dataset 20614.55 5814.44 3.55
FPv1.4. SP Medium Dataset 696.27 201.17 3.46
FPv1.5. SP Big Dataset 32.06 11.77 2.72
FPv1.D. DP Mark 533.97 165.64 3.22
FPv1.S. SP Mark 886.56 273.21 3.25
MicroFPMark 20614.55 5814.44 3.55
More Info
FPMark has a list of Frequently Asked Questions.
Purchase a license or request more information.